Cloud Disaster Recovery Services
NetSuite Backup Microsoft 365: Plans, Pricing & Services
Data Lake (unstructured and structured data) + Analytics (upto 5 KPI's)
$3000/Month
Why do you need a backup and disaster recovery plan?
Now more than ever, every business needs a serious disaster recovery to avoid the single point of failure and enable data protection for compliance and regulatory purposes. Without a tested business continuity plan ready, you're risking mission-critical applications and data, irreplaceable data, and your reputation with clients.
Functional Adaptability
Data analytic enables companies to identify potential opportunities that help find hidden bugs and streamlines operations to eliminate them and maximize profit.
Product Development
Data analytics delivers a combo of know-how-forecast capability that helps keep tracking business and give a solid brick to future outcomes.
Conversion Rate Optimization
Digital analytics boosts CRO that enables the business to create online visitor traffic and enhances the current business scenario.
Customer-oriented content
Data analytics effectively enhances a customer-based content that enables companies to personalize their services targeting a circle of customers.
Vast Edge is a global Oracle gold partner, a leading NetSuite SuiteLife partner, Cloud Select, MSP, and velocity designations with skills and expertise to build, deploy, run, and manage the Oracle Cloud Platform for both Oracle and non-Oracle workloads. Since 2016, Vast Edge has been one of the first partners to embrace Oracle cloud and was also mentioned in Forbes by Oracle for successfully migrating customers from other clouds and on-prem to Oracle cloud.
Vast Edge's Disaster Recovery as a Service Highlights
Vast Edge's backup and disaster recovery plan aids businesses in reducing downtime cost and revenue impact for planned and unplanned outages, thereby, ensures the uninterrupted performance of IT operations and the systems & applications you run on.
RECOVERY OBJECTIVES WITH SLAS
Vast Edge helps businesses to select their recovery point objective (RPO) and recovery time objective (RTO) to determine maximum tolerable hours for data recovery from minutes to days.
BACKUP AND RESTORE
Ensures that you have a spare copy of the volume in case something goes wrong with the primary copy with multiple copies of the same volume.
DATABASE STRATEGY
Active data guard to minimize the downtime associated with a planned or an unplanned outage.
SAFEGUARD NETWORKING
Vast Edge creates a dedicated, private connection between your on-premises data centre and public cloud infrastructure.
REAL-TIME DATA REPLICATION
Synchronous replication of database and applications residing on GFS using geo-replication, SAN, LAN, and WAN to reduce RTOs (Recovery Time Objectives).
CONTROLLED INFRASTRUCTURE
Vast Edge manages DR infrastructure for your organization in the cloud. Deploy compute instances across multiple availability domains to protect your applications from outages.
SECURITY
With public IP address and DNS switchover, Vast Edge adjusts the scaling between on-premises and your cloud setup to route all traffic to your backup solution at a time of disaster.
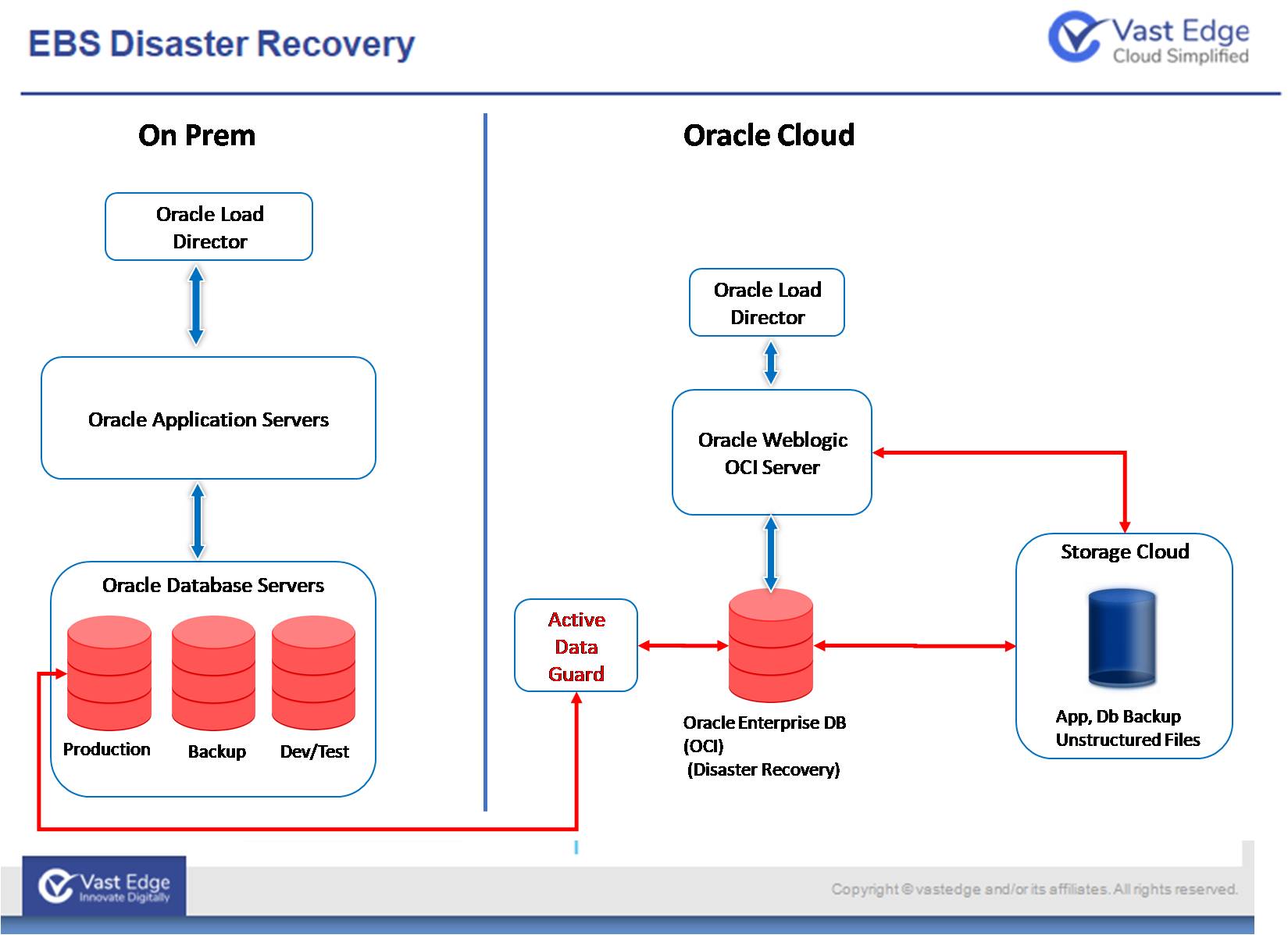
EBS Disaster Recovery
NetSuite Backup and Disaster Recovery
The Netsuite backup solution provided by Vast Edge enables businesses to leverage this near real-time data to export, extend, integrate, and better analyze the data set. This can also be leveraged for disaster recovery by using a limited feature GUI interface to manage daily activities. This data will be reintegrated with NetSuite using Oracle integration cloud. The NetSuite backup architecture is rock solid as it is encrypted, resides on the same network, and updates records in near real-time.
Vast Edge backup differentiators
- Incremental / differential backups of databases such as PostgreSQL, mysql, ms sql, and oracle
- Integrated with your cloud account for inherited governance policies
- Auto versioning, compression, encryption, file partitioning
- Active sync (one way or bi directional)
- Easy to use management console
- 90% cost savings with algorithms to help you archive old storage that is not being accessed anymore.
- Archive object backup's for added layer of security & peace of mind
- Unified view of storage across multiple clouds
- Storage redundancy and de duplication checks
- One click installer
Vast Edge has solved this Backup and recovery challenge by providing innovative, simple and automated tools for manage the data from a unified dashboard. This centralized dashboards provides modules to upload/ download data to/from multi-cloud repositories and servers. As an example, customers can now easily manage various versions of datasets and work with any version whenever required in case of data corruption, loss, or malware infection. Our automated backup and failover tools provide customers to keep their data records in the cloud and process them with centrally managed dashboard
ERP Backup
The ERP backup solution provided by Vast Edge can save you so much time and effort. ERP system serves as the memory for the businesses, so loss of memory means you are out of your business. Without risking your business, Vast Edge offers the copies of all the important data on your system and preserved in such a way that you can recover your data no matter what happens. Powerful backup and flexible options, including enhanced software, backup appliances, and cloud solutions offer flexibility and choice in managing backups. You can leverage backup and recovery directly from the cloud with an online backup and recovery service. Information can be lost at any time, making it imperative to ensure your data is always protected and recoverable. Our solution responds with new approaches to data protection tailored to your needs.
M365 Backup
With Vast Edge's M365 backup solution provides comprehensive protection for your Office 365 data, which is proven to safeguard your business from deletion, corruption and ransomware attack. It provides the total coverage by protecting the data in exchange online, teams, sharepoint online, OneDrive, data centers, SaaS applications, cloud-native workloads and more. We can ensure that your data is protected and accessible.
The benefits of Microsoft 365 backup are:
-Guard against accidental data loss
-Ransomware detection and recovery
-Data compliance monitoring
G Suite Backup
Vast Edge's G Suite backup is used to maintain control of the cloud data you’ve been entrusted to protect and to guard against G Suite app outages, failed 3rd party integrations, or ransomware attacks. This automated backup can take only 5 minutes for automatic backup 3 times a day or on-demand backup. It offers easy recovery by restoring fast by just few clicks, and full data control for your business while maintaining full visibility and control over your G Suite data.
The benefits of Microsoft 365 backup are:
-Robust, Automated Backup
-Easy Recovery
-Full Data Control
-Maintain full control of your data